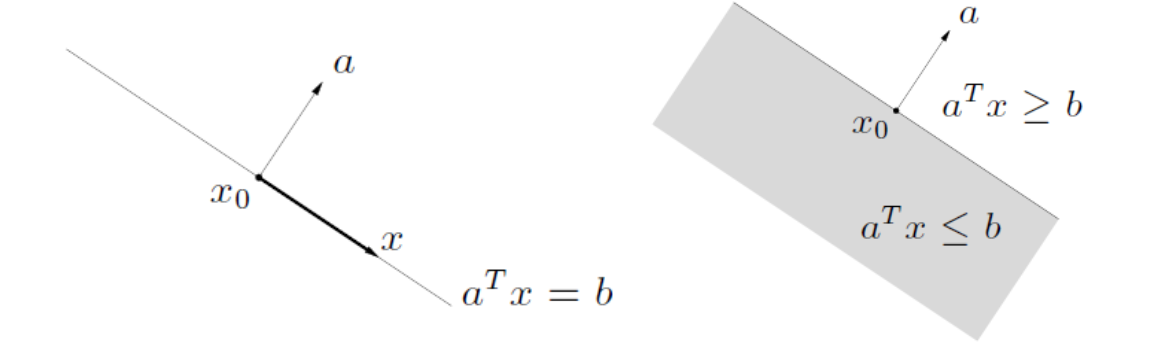引言和预备知识
引言
- Optimization
- 所谓最优化或优化问题通常泛指各类定量决策问题,即如
何在各种限制约束之下,寻找解决问题的最佳可⾏⽅案,
使得⼀项或者多项衡量指标达到某种意义上的最优。
- 这种⼒求达到最优或遵循最优的原则可以说是⼀种⾮常⾃
然和普遍存在的决策⽬标。通常,我们不仅想找到解决问
题的可⾏⽅案,还总是希望找到⼀个最好的可⾏⽅案。
- 甚⾄,这也是宇宙万物的⼀种变化规律。
-
优化的过程
-
数学规划的一般形式:
s.t. min(max)f(x)hi(x)=0,i=1,⋯,mgj(x)≤0,j=1,⋯,r
其中:
- x=(x1,…,xn)T:决策变量
- f:Rn→R:目标函数
- hi,gj:Rn→R,i=1,…,m,j=1,…,r:约束函数
- Ω={x∈Rn∣hi(x)=0,i=1,⋯,m;gj(x)≤0,j=1,⋯,r}:可行域
- 数学规划(Mathematical Programming)的分类
- 线性 / 非线性 (如:二次规划、凸规划)
- 光滑 / 非光滑
- 凸 / 非凸
- 连续 / 离散 (如:整数规划、混合整数规划)
- 静态 / 动态 (如:动态规划)
- 确定性 / 随机性 (如:随机规划、鲁棒优化)
- 有约束 / 无约束
预备知识
线性代数基础知识
-
向量和矩阵
- 向量通常用小写字母表示,矩阵通常用大写字母表示。
- 长度为 n 的实向量空间记为 Rn。
- m×n 阶实矩阵空间记为 Rm×n。
- 若矩阵 A∈Rn×n 满足 A=AT,则称 A 为对称矩阵。
- 对称矩阵 A 称为正定(记作 A≻0),如果
xTAx>0,∀x=0, x∈Rn
- 若对任意 x∈Rn,有
xTAx≥0,
则称 A 为半正定(记作 A⪰0)。
-
范数
-
向量范数
-
l1 范数:
∥x∥1=∑i=1n∣xi∣
-
欧几里得范数(l2 范数):
∥x∥2=xTx=∑i=1nxi2
-
l∞ 范数:
∥x∥∞=max1≤i≤n∣xi∣
-
lp 范数(p≥1):
∥x∥p=(∑i=1n∣xi∣p)p1
-
加权范数(由正定矩阵诱导):
∥x∥G=xTGx,其中 G 为对称正定矩阵(即 G≻0)
-
l0 “范数”:
∥x∥0= 向量中非零元素的个数。
严格来说,l0 并不满足范数的齐次性,因此不是真正的范数。
-
向量范数的性质
-
内积定义:
向量 x 与 y 的内积记为
x⋅y≡xTy=i=1∑nxiyi
-
Hölder 不等式:
对任意 p,q≥1 满足 p1+q1=1,有
∣xTy∣≤∥x∥p∥y∥q
-
对偶范数表示:
lp 范数可通过对偶形式表示为
∥x∥p=∥y∥q≤1maxxTy,其中 p1+q1=1
-
特例 1:p=q=2(Cauchy–Schwarz 不等式)
∣xTy∣≤∥x∥2∥y∥2,∥x∥2=∥y∥2≤1maxxTy
-
特例 2:p=1, q=∞
∣xTy∣≤∥x∥1∥y∥∞
且
∥x∥1=∥y∥∞≤1maxxTy,∥x∥∞=∥y∥1≤1maxxTy
-
欧几里得范数与内积的关系:
∥x∥22+∥y∥22=∥x+y∥22−2xTy=∥x−y∥22+2xTy=21(∥x+y∥22+∥x−y∥22)≥2∣xTy∣
- 向量范数的等价性:
在 Rn 中,任意两种向量范数 ∥⋅∥∗ 与 ∥⋅∥+ 均满足c1∥x∥+≤∥x∥∗≤c2∥x∥+,其中 c1,c2>0 为常数
特别地,常见范数之间有如下具体关系:∥x∥2≤∥x∥1≤n∥x∥2∥x∥∞≤∥x∥2≤n∥x∥∞∥x∥∞≤∥x∥1≤n∥x∥∞
-
矩阵范数
-
最常用的矩阵范数是由向量范数诱导的范数(也称为算子范数或诱导范数),定义为:
∥A∥p=x=0max∥x∥p∥Ax∥p
-
1-范数(列和范数):
∥A∥1=1≤j≤nmaxi=1∑m∣aij∣
即所有列向量绝对值之和的最大值。
-
2-范数(谱范数):
∥A∥2=λmax(ATA)
其中 λmax(ATA) 是 ATA 的最大特征值。
-
∞-范数(行和范数):
∥A∥∞=1≤i≤mmaxj=1∑n∣aij∣
即所有行向量绝对值之和的最大值。
-
Frobenius 范数(弗罗贝尼乌斯范数):
∥A∥F=tr(ATA)=i=1∑mj=1∑naij2
-
迹(Trace)的性质:
tr(ATB)=j=1∑ni=1∑maijbij
即两个矩阵对应元素乘积之和(等价于向量化后的内积)。
-
Frobenius 范数的展开公式:
∥A+B∥F2=∥A∥F2+∥B∥F2+2tr(ATB)
-
正交矩阵(Orthogonal Matrix)的性质:
若 Q 为正交矩阵,则满足:
QQT=QTQ=I(因此 QT=Q−1)
并且保持以下范数不变:
∥QA∥F=∥A∥F,∥QA∥2=∥A∥2,∥Qx∥2=∥x∥2
-
Sherman-Morrison公式
-
假设原始矩阵 A∈Rn×n,且扰动后的矩阵为 B=A+uvT,其中 u,v∈Rn。
-
如果已知 A−1,如何高效地计算扰动矩阵 B 的逆矩阵?
-
步骤 1:求解 (I+uvT)−1
首先,假设矩阵 (I+uvT) 的逆矩阵形式为 (I+ρuvT),则 ρ 的值为:
(I+uvT)(I+ρuvT)=I+[1+ρ(1+vTu)]uvT
由此得出:
ρ=−1+vTu1
因此:
(I+uvT)−1=I−1+vTuuvT
-
步骤 2:利用上述关系计算 (A+uvT)−1
其次,利用上述关系,我们有:
(A+uvT)−1=(A(I+A−1uvT))−1=(I+A−1uvT)−1A−1=(I−1+vTA−1uA−1uvT)A−1=A−1−1+vTA−1uA−1uvTA−1
其中要求 1+vTA−1u=0。
-
通过以上步骤,我们可以高效地计算出扰动矩阵 B=A+uvT 的逆矩阵,而不需要重新进行完整的矩阵求逆运算。这种方法在处理大型矩阵时特别有用,因为它避免了高计算复杂度的直接求逆过程。
-
o, O 记号
-
设 g 是一个实变量的实值函数。
-
记号 g(x)=O(x) 表示当 x→0 时,g(x) 趋于零的速度至少与 x 一样快。
更精确地,存在常数 K>0,使得
xg(x)≤K当 x→0.
-
记号 g(x)=o(x) 表示 g(x) 趋于零的速度比 x 更快,即
x→0limxg(x)=0.
-
在算法分析中,大 O 符号通常用于描述渐近上界(当 n→∞):
g(n)=O(f(n))若存在 C>0 使得 g(n)≤Cf(n) 对足够大的 n 成立.
- 例如:3n3+2n2+5=O(n3)。若算法复杂度为 O(n3),则输入规模 n 翻倍时,运行时间约增至 8 倍(对大 n 而言)。
-
在数值分析或泰勒展开中,大 O 和小 o 常用于描述逼近误差(当 h→0):
g(h)=O(f(h))若 ∣g(h)∣≤C∣f(h)∣ 当 h→0,
g(h)=o(f(h))若 h→0limf(h)g(h)=0.
-
例如,当 ∣h∣<1 时:
1−h1=1+h+h2+h3+⋯=1+h+O(h2),
且更精细地,
1−h1=1+h+h2+o(h2).
多元函数分析
-
梯度和Hessian矩阵
-
设 f 是一个 n 元实值函数:
f(x)=f(x1,x2,…,xn)
-
函数 f 的一阶偏导数组成的向量称为梯度(gradient),记作 ∇f(x):
∇f(x)=(∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x))T
-
函数 f 的二阶偏导数组成的矩阵称为Hessian 矩阵(或简称 Hessian),记作 ∇2f(x),其 (i,j) 元素定义为:
[∇2f(x)]ij=∂xi∂xj∂2f(x)
-
若 f 的二阶偏导数连续,则 Hessian 矩阵是对称的,即:
∂xi∂xj∂2f(x)=∂xj∂xi∂2f(x)
-
练习:计算以下函数的梯度与 Hessian 矩阵:
f(x1,x2)=2x14+3x12x2+2x1x23+4x22
解:
∇f(x)=(8x13+6x1x2+2x233x12+6x1x22+8x2),∇2f(x)=(24x12+6x26x1+6x226x1+6x2212x1x2+8)
-
练习:计算以下函数的梯度与 Hessian 矩阵:
f(x)=21xTQx−bTx,其中 Q∈Rn×n 为对称矩阵
解:
∇f(x)=Qx−b,∇2f(x)=Q
-
雅可比矩阵
-
考虑向量值函数 f:Rn→Rm:
f(x)=f1(x)f2(x)⋮fm(x)
-
其 Jacobian 矩阵 是一个 m×n 矩阵,第 i 行第 j 列元素为 ∂fi/∂xj,即:
Jf(x)=[∂xj∂fi]
-
练习:计算
f(x)=sinx1+cosx2e3x1+x224x13+7x1x22
的 Jacobian。
-
Jacobian 为:
cosx13e3x1+x2212x12+7x22−sinx22x2e3x1+x2214x1x2
-
链式法则
-
求复合函数导数的法则称为链式法则(chain rule)。
-
考虑函数 g(x)=g(x1,…,xn),其中每个变量 xi 本身是另一组变量 t1,…,tm 的函数,即 xi=xi(t1,…,tm)。
-
定义复合函数 h(t)=g(x(t)),则其梯度满足:
∇h(t)=∇x(t)T∇g(x(t))
其中 ∇x(t) 是向量值函数 x(t) 的 Jacobian 矩阵(大小为 n×m),因此 ∇h(t)∈Rm。
-
例如:若 f:Rn→R 连续可微,定义 g(x)=f(Ax−b),其中 A∈Rn×n,b∈Rn,则
∇g(x)=AT∇f(Ax−b)
-
方向导数
-
若 f 连续可微,p∈Rn,则 f 在点 x 沿方向 p 的方向导数定义为:
∂p∂f(x)≡ϵ→0limϵf(x+ϵp)−f(x)=pT∇f(x)
-
为验证该公式,定义辅助函数:
ϕ(α)=f(x+αp)=f(y(α)),其中 y(α)=x+αp
-
注意到:
ϵ→0limϵf(x+ϵp)−f(x)=ϵ→0limϵϕ(ϵ)−ϕ(0)=ϕ′(0)
-
由链式法则,
ϕ′(α)=i=1∑n∂yi∂f(y(α))pi=pT∇f(y(α))
因此 ϕ′(0)=pT∇f(x),即方向导数等于梯度与方向向量的内积。
-
泰勒级数
-
泰勒级数(Taylor series)是一种在指定点 x0 附近近似函数 f 的工具,其近似结果是一个多项式。
-
只要函数具有足够阶的导数,泰勒级数就可应用,常见用途包括:
- 在 x0 附近估计难以直接计算的函数值;
- 利用近似多项式的导数或积分来估计原函数的导数或积分;
- 推导求根、优化等数值算法。
-
对一元函数 f(具有 n 阶连续导数),在点 x0 处的 n 阶泰勒展开为:
f(x0+p)≈f(x0)+pf′(x0)+2!1p2f′′(x0)+⋯+n!pnf(n)(x0)
-
前两项给出函数在 x0 处的切线方程:
y=f(x0)+(x−x0)f′(x0)
-
前三项给出二次近似。
-
对多元函数 f:Rn→R,二阶泰勒展开为:
f(x0+p)=f(x0)+pT∇f(x0)+21pT∇2f(x0)p+⋯
-
泰勒级数还有带余项的形式。若取前三项,则:
- 一元情形:
f(x0+p)=f(x0)+pf′(x0)+21p2f′′(ξ)
- 多元情形:
f(x0+p)=f(x0)+pT∇f(x0)+21pT∇2f(ξ)p
其中 ξ 是介于 x0 与 x0+p 之间的某一点。
-
通过分析余项的上界,可以评估近似的精度。更高阶项虽可写出,但符号复杂,本课程不作要求。
-
练习:考虑函数
f(x1,x2)=x13+5x12x2+7x1x22+2x23
在点 x0=(−2,3)T 处,用二阶泰勒公式近似计算 f(−1.9,3.2)。
已知:
f(x0)=−20,∇f(x0)=(15−10),∇2f(x0)=(1822228)
令 p=(−1.9,3.2)T−(−2,3)T=(0.1,0.2)T,则二阶泰勒近似为:
f(x0+p)≈f(x0)+pT∇f(x0)+21pT∇2f(x0)p
计算各项:
- pT∇f(x0)=(0.1)(15)+(0.2)(−10)=1.5−2.0=−0.5
- pT∇2f(x0)p=(0.1,0.2)(1822228)(0.10.2)=(0.1)(18⋅0.1+22⋅0.2)+(0.2)(22⋅0.1+8⋅0.2)=0.62+0.76=1.38
因此:
f(−1.9,3.2)≈−20+(−0.5)+21(1.38)=−20−0.5+0.69=−19.81
凸集与凸函数
-
仿射
-
一个集合 C 称为仿射集(affine set),如果对任意 x,y∈C 和任意实数 α∈R,都有
αx+(1−α)y∈C.
-
当 x 和 y 是 Rn 中两个不同的点时,所有形如 z=αx+(1−α)y(α∈R)的点构成通过 x 和 y 的直线。
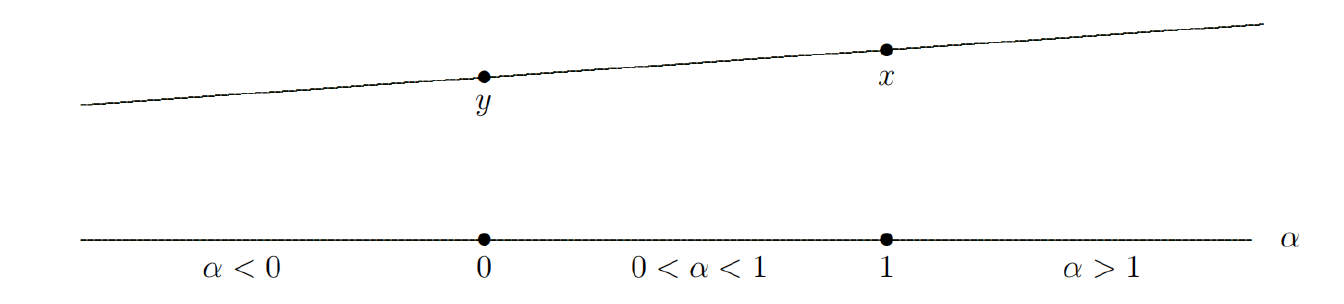
-
由仿射集的定义可归纳得出:
若 C 是仿射集,x1,…,xk∈C,且系数满足 α1+⋯+αk=1,则
α1x1+⋯+αkxk∈C.
-
换句话说,仿射集包含其任意点的仿射组合。
-
仿射组合(Affine Combination)定义为:
y=i=1∑kαixi,其中 i=1∑kαi=1.
-
例如,集合 {x∣Ax=b}(线性方程组的解集)是一个仿射集。
-
给定任意集合 C,其所有仿射组合构成的集合称为 C 的仿射包(affine hull),记作 affC,即
affC={i=1∑kαixix1,…,xk∈C,i=1∑kαi=1,k∈N}.
-
凸
-
一个集合 C 称为凸集(convex set),如果对任意 x,y∈C 和任意 α∈[0,1],都有
αx+(1−α)y∈C.
-
换句话说,若 x 和 y 属于 C,则连接 x 与 y 的线段也完全包含在 C 中。
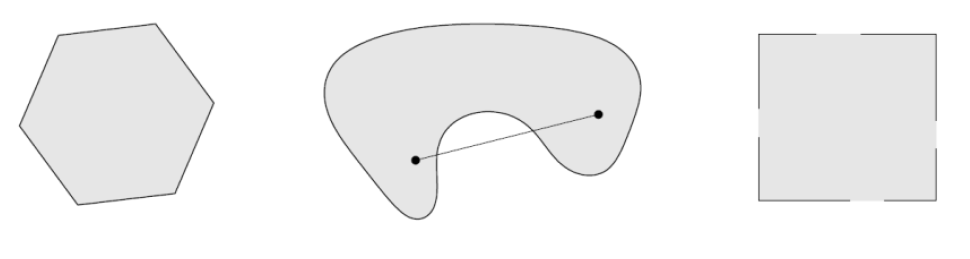
-
点 αx+(1−α)y(其中 α∈[0,1])称为 x 与 y 的凸组合(convex combination)。
-
凸组合的一般形式:
y=i=1∑kαixi,其中 αi≥0,i=1∑kαi=1.
-
一个集合是凸集,当且仅当它包含其任意点的所有凸组合。
-
给定集合 C,其所有凸组合构成的集合称为 C 的凸包(convex hull),记作 convC,即
convC={i=1∑kαixix1,…,xk∈C,αi≥0,i=1∑kαi=1}.
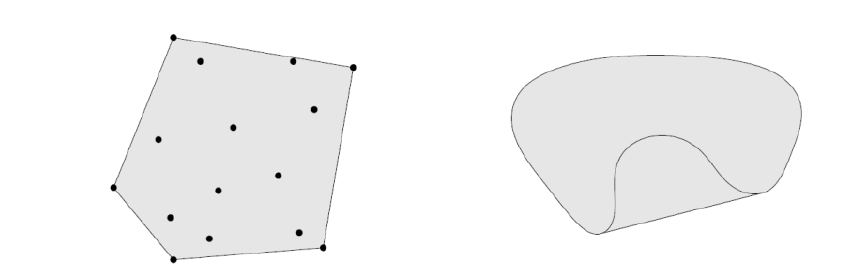
-
凸集的基本性质:
- 若 C1 和 C2 是凸集,则以下集合也是凸集:
- βC1(标量乘法,β∈R),
- C1+C2={x+y∣x∈C1,y∈C2}(Minkowski 和),
- C1−C2={x−y∣x∈C1,y∈C2},
- C1∩C2(交集,若非空)。
- 按约定,空集 ∅ 被视为凸集。
-
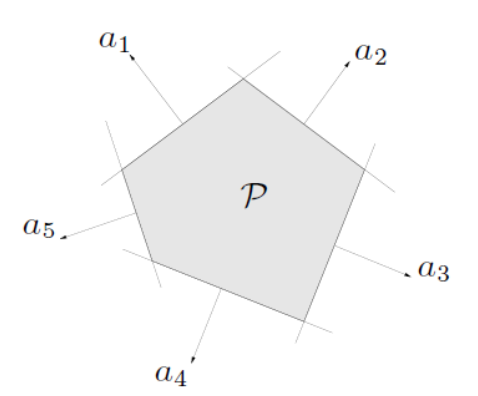
超平面和半空间
H={x∣aTx=b},a=0
-
范数球和范数锥
-
范数球(Norm Ball):以 xc 为中心、半径为 r 的范数球定义为
B(xc,r)={x∣∥x−xc∥≤r}
常见的范数球包括:
- l1-球:{x∣∥x−xc∥1≤r}
- l2-球(欧几里得球):{x∣∥x−xc∥2≤r}
- l∞-球:{x∣∥x−xc∥∞≤r}
-
范数锥(Norm Cone):
{(x,t)∣∥x∥2≤t}⊆Rn+1
其中,欧几里得范数锥也称为二阶锥(Second-Order Cone)或冰激凌锥(Ice-Cream Cone)。
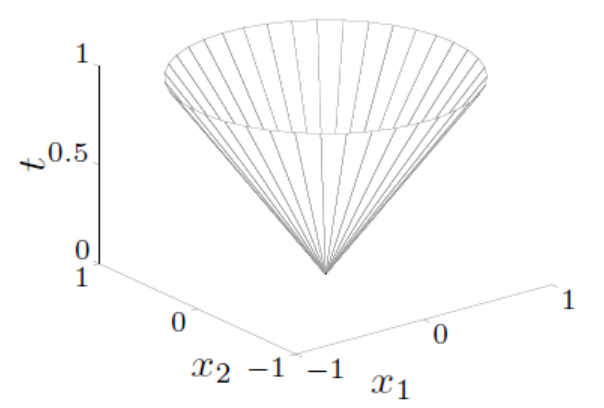
- 范数球和范数锥都是**凸集**。
-
锥和锥组合
-
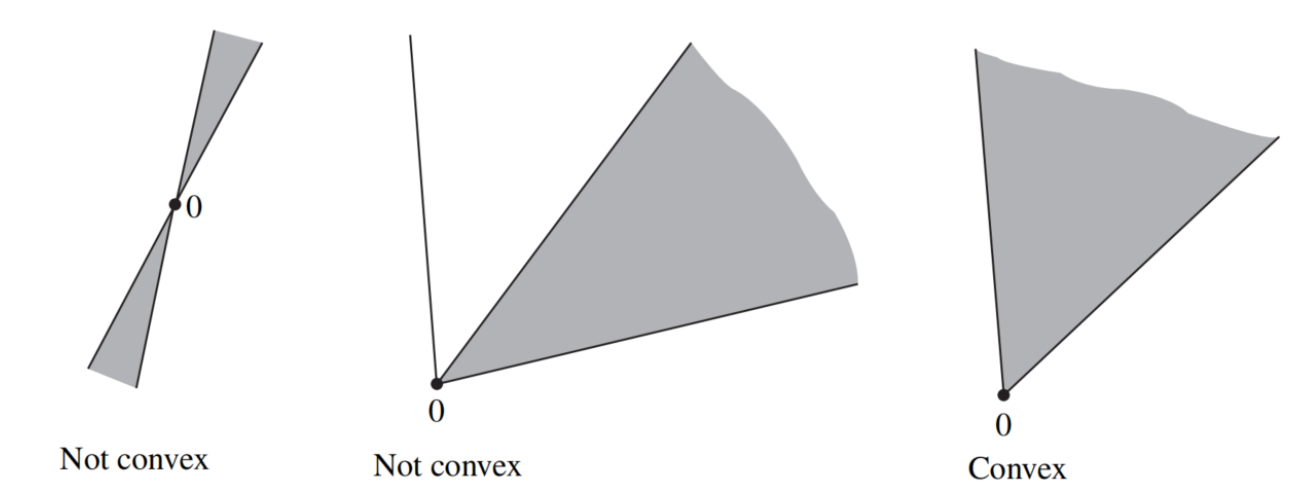
一个集合 C 称为锥(cone),如果对任意 x∈C 和任意 θ≥0,都有
θx∈C.
-
锥组合(Conic Combination,或称非负组合)是指形如
x=θ1x1+θ2x2
的线性组合,其中 θ1≥0,θ2≥0。(可推广到任意有限项)
-
一个集合称为凸锥(convex cone),如果它包含其任意点的所有锥组合。
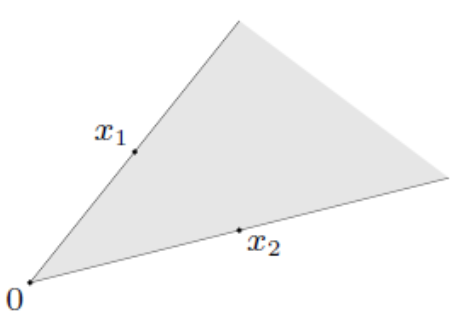
-
等价地,集合 C 是凸锥,当且仅当对任意 x,y∈C 和任意 α,β≥0,都有
αx+βy∈C.
-
总结
-
凸集分离
设 D1,D2⊂Rn 为两个非空凸集。若存在非零向量 a∈Rn 和实数 β,使得
D1⊂H+={x∈Rn∣aTx≥β},D2⊂H−={x∈Rn∣aTx≤β},
则称超平面
H={x∈Rn∣aTx=β}
分离(separates)集合 D1 和 D2。
进一步,如果
D1⊂Ho+={x∈Rn∣aTx>β},D2⊂Ho−={x∈Rn∣aTx<β},
则称超平面 H 严格分离(strictly separates)D1 和 D2,其中 Ho+ 和 Ho− 分别表示 H+ 和 H− 的内部。
-
投影定理
设 D⊂Rn 是一个非空闭凸集,点 y∈Rn 但 y∈/D。
-
存在唯一最近点:
存在唯一的点 xˉ∈D,使得
∥xˉ−y∥=x∈Dinf∥x−y∥.
-
最优性条件:
xˉ∈D 是 y 到 D 的最近点,当且仅当
(x−xˉ)T(xˉ−y)≥0,∀x∈D.
-
证明:
(1) 存在唯一性
- 距离函数 ∥x−y∥ 在闭集 D 上连续,且 D 非空 → 最小值可达(存在性)。
- 因为 ∥x−y∥2 是严格凸函数,而 D 是凸集 → 最小值点唯一。
(2) 最优性条件
-
必要性:若 xˉ 是最近点,则对任意 x∈D,线段上的点 zθ=xˉ+θ(x−xˉ)∈D(由凸性)。
函数 θ↦∥zθ−y∥2 在 θ=0 处最小,其导数 ≥0,即
dθdθ=0∥zθ−y∥2=2(x−xˉ)T(xˉ−y)≥0.
-
充分性:若 (x−xˉ)T(xˉ−y)≥0 对所有 x∈D 成立,则
∥x−y∥2=∥xˉ−y∥2+2(x−xˉ)T(xˉ−y)+∥x−xˉ∥2≥∥xˉ−y∥2,
所以 xˉ 确实是最接近 y 的点。
-
点与凸集分离定理
设 D⊂Rn 是一个非空闭凸集,点 y∈Rn 但 y∈/D。则存 在非零向量 a∈Rn 和实数 β,使得
aTx≤β<aTy,∀x∈D.
这表示存在超平面
H={x∈Rn∣aTx=β}
严格分离点 y 与集合 D:整个集合 D 位于超平面的一侧(含边界),而点 y 严格位于另一侧。
-
证明:
设 D⊂Rn 是非空闭凸集,y∈/D。
由投影定理,存在唯一的 xˉ∈D 使得 ∥xˉ−y∥ 最小,且满足
(x−xˉ)T(xˉ−y)≥0,∀x∈D.
整理不等式得:
xT(y−xˉ)≤xˉT(y−xˉ),∀x∈D.
令 a=y−xˉ。因为 y=xˉ,所以 a=0。
上式变为:
aTx≤aTxˉ,∀x∈D.
又因为 aTy=aT(xˉ+a)=aTxˉ+∥a∥2>aTxˉ,
所以对所有 x∈D 有:
aTx≤aTxˉ<aTy.
令 β=aTxˉ,则
aTx≤β<aTy,∀x∈D,
即超平面 {x∣aTx=β} 严格分离点 y 与集合 D。
-
支撑超平面
-
设 D⊂Rn 是非空集合,点 xˉ∈∂D(即 xˉ 是 D 的边界点)。
若存在非零向量 a∈Rn,使得
D⊂Hxˉ+={x∈Rn∣aT(x−xˉ)≥0}
或
D⊂Hxˉ−={x∈Rn∣aT(x−xˉ)≤0},
则称超平面
Hxˉ={x∈Rn∣aT(x−xˉ)=0}
为集合 D 在点 xˉ 处的一个支撑超平面。
-
若 D 是非空凸集,则在其每一个边界点处都存在至少一个支撑超平面。
-
两个凸集的分离定理
- 设 D1,D2⊂Rn 为两个非空凸集,且 D1∩D2=∅。
则存在一个超平面分离 D1 与 D2,即存在非零向量 a∈Rn,使得
aTx≤aTy,∀x∈D1,y∈D2.
-
证明:
令 D=D1−D2={x−y∣x∈D1,y∈D2}。
由于 D1 和 D2 均为凸集,其差集 D 也是凸集;又因 D1∩D2=∅,故 0∈/D。
考虑闭包 D,它仍是凸集且不包含原点。由点与闭凸集的分离定理,存在非零向量 a∈Rn,使得
aTz≤0,∀z∈D.
对任意 x∈D1、y∈D2,有 z=x−y∈D,代入得
aT(x−y)≤0⟹aTx≤aTy,
即所求分离不等式成立。
-
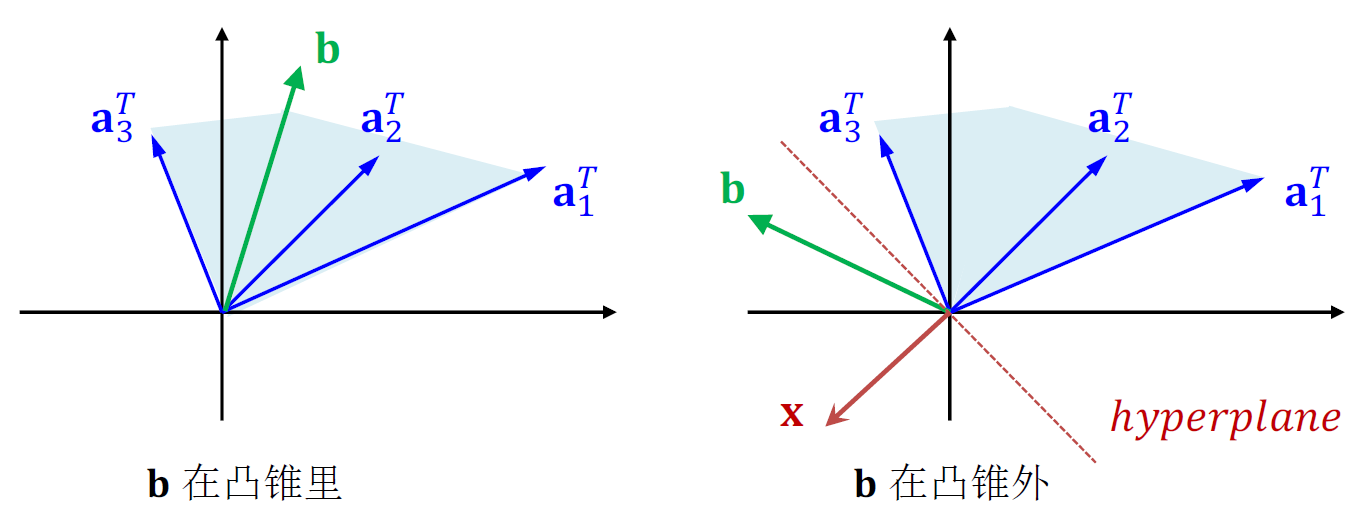
Farkas 引理
设 A∈Rm×n,b∈Rn。则以下两个系统中有且仅有一个有解:
-
系统 (1):
ATy=b,y≥0
-
系统 (2):
Ax≤0,bTx>0
其中 x∈Rn,y∈Rm。
-
几何理解:
-
凸函数
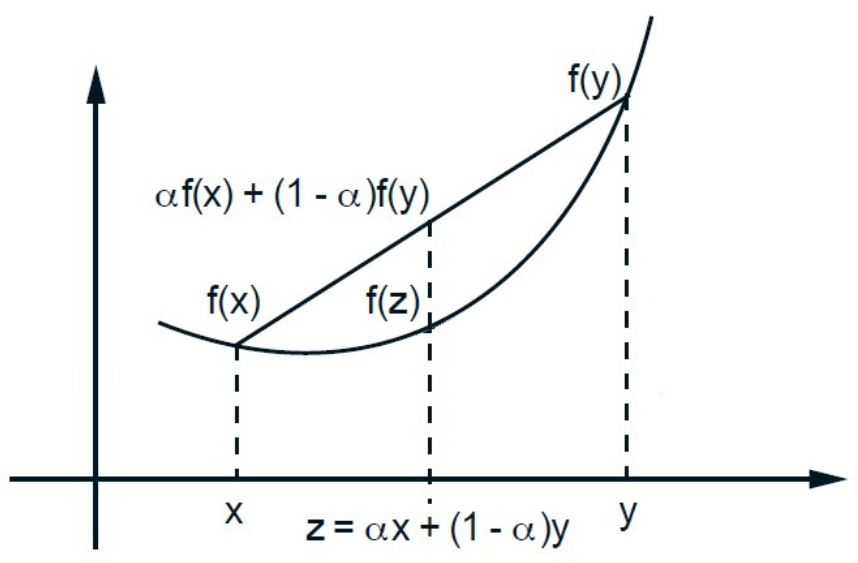
- 设 C⊂Rn 为凸集,函数 f:C→R 称为 凸函数,如果对任意 x,y∈C 和任意 α∈(0,1),都有
f(αx+(1−α)y)≤αf(x)+(1−α)f(y).
- 若上述不等式对所有 x=y∈C 和 α∈(0,1) 严格成立,即
f(αx+(1−α)y)<αf(x)+(1−α)f(y),
则称 f 为 严格凸函数。
- 一阶条件(适用于定义在凸集 C 上的可微函数 f):
-
函数 f 在 C 上是凸函数,当且仅当
f(y)≥f(x)+∇f(x)T(y−x),∀x,y∈C.
-
函数 f 在 C 上是严格凸函数,当且仅当
f(y)>f(x)+∇f(x)T(y−x),∀x,y∈C,x=y.
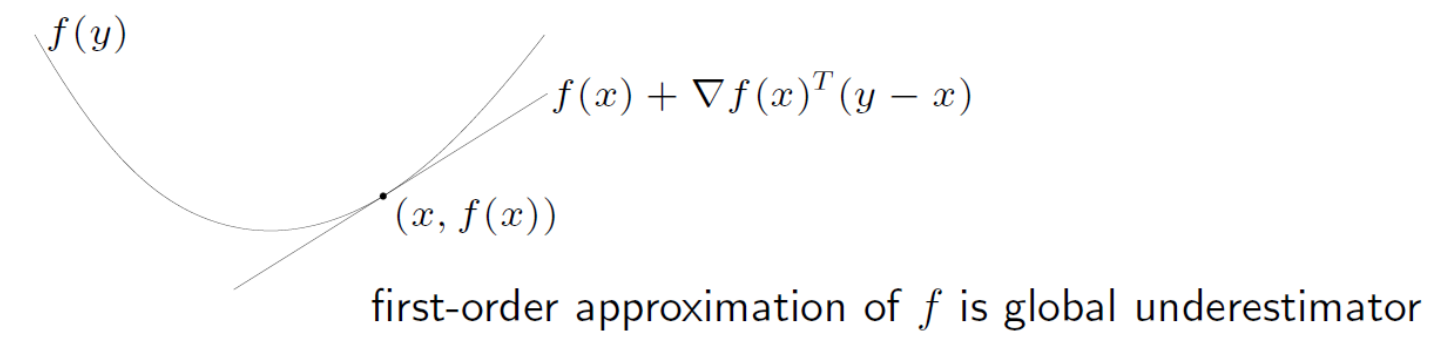
该条件表明:凸函数在其任意点处的一阶泰勒展开是全局下界;严格凸时,该下界在其他点严格成立。
-
二阶条件(适用于定义在开凸集 C⊂Rn 上的二阶连续可微函数 f):
-
函数 f 在 C 上是凸函数,当且仅当其 Hessian 矩阵半正定,即
∇2f(x)⪰0,∀x∈C.
-
若对所有 x∈C,Hessian 矩阵正定,即
∇2f(x)≻0,
则 f 是严格凸函数。
(注:这是严格凸的充分条件,但非必要条件。)
-
一维凸函数的例子:
-
指数函数:f(x)=eax,其中 a∈R,在 R 上是凸函数。
-
幂函数:f(x)=xα,定义在 x>0 上,当 α≥1 或 α≤0 时为凸函数。
-
负对数函数:f(x)=−lnx,在 x>0 上是凸函数。
-
负熵函数:f(x)=xlnx,在 x>0 上是凸函数(约定 0ln0=0 可将其连续延拓至 x=0)。
-
需要注意的是,并非所有凸函数都是可微的。
- 一个简单的不可微凸函数例子是绝对值函数:
f(x)=∣x∣={x,−x,若 x≥0,若 x<0.
该函数在 x=0 处不可导,但在整个 R 上是凸函数。
-
上方图
- 设 f 是定义在集合 S⊂Rn 上的实值函数。
函数 f 的上镜图(epigraph)定义为
epif={(x,μ)∈Rn+1x∈S,μ≥f(x)}.
它表示 Rn+1 中位于函数图像之上或恰好在图像上的所有点构成的集合。
- 设 S⊂Rn 是非空凸集,则函数 f:S→R 是凸函数 当且仅当 其上镜图 epif 是 Rn+1 中的凸集。
这一定理建立了凸函数与凸集之间的等价关系,常用于证明某些函数的凸性。
-
水平集 (Level Set)
假设 f 是定义在 L⊂Rn 上的实值函数。对于任意 α∈R,集合
Lα={x∣f(x)≤α,x∈L}
称为函数 f 的 α 水平集。
若 L⊂Rn 是非空凸集,且 f 是定义在 L 上的凸函数,则对任意 α∈R,水平集 Lα 是一个凸集。
- 水平集是所有满足 f(x)≤α 的点 x 构成的集合。
- 如果函数 f 是凸函数,并且其定义域是凸集,则该函数的所有水平集也是凸集。这为我们判断某些集合是否为凸提供了一种方法。
-
凸规划
-
凸规划(Convex Programming)是指如下形式的优化问题:
x∈Sminf(x)
其中,可行域 S⊂Rn 是一个凸集,目标函数 f 在 S 上是凸函数。
-
示例:
考虑问题
mins.t.f(x)gi(x)≥0,i=1,…,m
若目标函数 f(x) 是凸函数,且每个约束函数 gi(x) 是凹函数,则该问题是凸规划。
-
理由:
由于 gi 是凹函数,集合 {x∣gi(x)≥0} 是凸集(凹函数的上水平集为凸集)。
多个凸集的交集仍是凸集,因此可行域
S=i=1⋂m{x∣gi(x)≥0}
是凸集。结合 f 为凸函数,该问题满足凸规划的定义。
-
可行性
-
考虑如下形式的约束条件:
gi(x)gi(x)=0,≥0,i∈E(等式约束)i∈I(不等式约束)
-
满足所有约束条件的点称为可行点(feasible point)。
所有可行点构成的集合称为可行域(feasible region)或可行集。
-
在一个可行点 xˉ 处,不等式约束 gi(x)≥0 被称为:
- 起作用(active / binding),如果 gi(xˉ)=0(即该点位于约束边界上);
- 不起作用(inactive / nonbinding),如果 gi(xˉ)>0(即该点位于约束内部)。
-
所有等式约束在任意可行点处均视为起作用。
-
在可行点 xˉ 处的起作用集(active set)定义为在该点处所有起作用约束(包括全部等式约束和满足 gi(xˉ)=0 的不等式约束)的下标集合。
-
所有满足至少一个不等式约束起作用(即 gi(x)=0 对某个 i∈I 成立)的可行点,构成可行域的边界。
-
其余的可行点(即所有不等式约束均严格成立:gi(x)>0 对所有 i∈I)称为可行域的内点。
-
对于无约束优化问题,可行集 S 即为整个 Rn。
-
最优性
-
若点 x∗ 满足
f(x∗)≤f(x),∀x∈S,
则称 x∗ 为函数 f 在集合 S 上的全局最小值点(global minimizer)。
-
若进一步满足
f(x∗)<f(x),∀x∈S 且 x=x∗,
则称 x∗ 为 f 在 S 上的严格全局最小值点(strict global minimizer)。